Managing Assessment Data
 INTRODUCTORY
INTRODUCTORY
“You should look at this section if you have only a limited idea of what is involved in managing assessment data.”
Assessment is designed to collect data from students that can provide insights into their skills and knowledge.There is a critical phase between the implementation of testing and the commencement of analysis in which the data collected needs to be carefully managed. This includes how the data is recorded, how it is transferred between individuals, how it is kept secure and the development of a data codebook.
Data is likely to be collected in one of three ways:
- Student write their responses on a paper test form;
- Students record their responses on an optical mark recognition (OMR) sheet; or
- Students enter their responses on a digital device.
In each case the entry of data–the process that is required to transfer student responses into data that is saved in a spreadsheet, for example–has to be done very carefully.
If students write their responses on a paper test form, as is the case in most school and classroom based testing as well as much large scale testing, scanning or manual data entry will be required to enter the data. At a small scale this is relatively easy to do accurately, although will require back and forth checking to get right.
At a large scale, manual data entry can lead to significant errors unless it is tightly controlled. This means manuals and training for data entry operators and–where possible–data entry processes that are designed to prevent errors where possible. For example, restricting cells in a spreadsheet so that they can only accept certain numbers. In addition, regular monitoring and checking will be required to make sure that any systematic errors are both identified and addressed.
OMRs are regarded as a much more reliable way to collect data in large scale student assessments but there are three key sources of error that need to be carefully controlled.First, students may not mark OMRs either accurately or clearly, and they will need to be instructed how to do so. Second, the machines used to scan OMRs need to be carefully set up and regularly checked to ensure that they are converting student marks into correct data. Third, the dataset that is derived from scanning OMRs needs to be checked in case there are any systematic errors, and this requires another layer of checking.
Digital devices–usually computers, tablets or phones–are increasingly used in assessment programmes and the programme used can automatically collect assessment data. It should not be assumed, however, that data will be collected accurately. Again, careful checking is required to detect any errors and to remediate any problems found.
Data entry processes often go wrong, and can cause huge problems for data analysts, who will have to examine the data collection and data entry processes in order to try to find out what has caused data anomalies. This process can cause severe delays in data reporting and therefore it is better to try to prevent any problems before the data is sent for analysis.
In addition to careful data entry which involves comprehensive data validation checks, two keys ways in avoiding problems in data entry are, first, creating test forms and contextual questionnaires that are designed to minimise the possibility of error. Second, undertaking robust data cleaning processes.
Data cleaning involves identifying and then removing inconsistencies in the data. Examples of inconsistencies include missing data, data that has been wrongly coded or data that has been entered in the wrong format. Data cleaning can take longer than data analysis, depending on the accuracy of data collection processes but it is essential. The basic rule is‘ rubbish in, rubbish out’–if raw data is used in data analysis then the results are very unlikely to present an accurate picture of student skills and knowledge.
To find out more about data management, move to #Intermediate.
 INTERMEDIATE
INTERMEDIATE
“You should look at this section if you already know something about managing assessment data and would like to know more”
 Data management is very important in making sure that data collected from students during an assessment programme can provide an accurate picture of their skills and knowledge. Data is collected as written responses on test forms, as marks on optical mark recognition (OMR) sheets or via digital devices. In addition to running check and monitoring how data is collected and entered, it is also essential to keep it secure.
Data management is very important in making sure that data collected from students during an assessment programme can provide an accurate picture of their skills and knowledge. Data is collected as written responses on test forms, as marks on optical mark recognition (OMR) sheets or via digital devices. In addition to running check and monitoring how data is collected and entered, it is also essential to keep it secure.
Data security ensures that no-one has the opportunity to change the data, for example to make it appear that students performed better than they actually did. This can only be achieved through having very clear protocols in place about who collects data, where it is stored, how it is transferred and who can access it, with detailed records kept at every step in the process.
Security is equally important regardless of the method used to collect data from students. There are advantages and disadvantages of different approaches to testing. The storage and security of paper test forms needs to be carefully handled to prevent them being leaked in advance. Digital devices can be locked to prevent access until the moment that testing begins but people can be concerned about what data is collected about them and where it is stored and it is still possible for there to be security breaches with digital devices, and so controls need to be in place to prevent these.
Throughout the processes involved in data collection and data entry, a log should be kept in which all activities and any changes are recorded. For example, the log may record what time students completed the test, how test forms were collected, how they were stored, how they were provided to data entry operators, who undertook data entry, what quality assurance processes were used, and so on. This may seem laborious, but it will be really helpful if data cleaning processes detect any anomalies and it is necessary to investigate possible causes (something that is a very common occurrence).
Data cleaning involves identifying and then removing inconsistencies in the data. These include duplicates; inconsistencies in data entry (for example ‘a’ instead of ‘A’ or ‘three’ instead of 3); unwanted outliers (for example if the age for a grade 5 student is recorded as 79); and coding missing data as either missing or skipped (or imputing it from other sources).
Sometimes major anomalies–such as the data from a school showing that every student has the same response to every item–may require further steps such as checking with that school (and with field operators) about possible causes. In the most serious cases–particularly where cheating is suspected–it may be necessary to remove all of that data.
Such anomalies can be reduced if any perverse incentives to misreport student performance are removed. For example, if schools or teachers are rewarded for student scores on a test then there is an obvious incentive for them to ensure that reported data indicates that students performed well. Major errors can also be minimised through training and support in data entry and the use of easy-to-understand data reporting mechanisms.
It is important to note that anomalies can be found whatever the mode of delivery and data entry–even data collected automatically during digital assessment delivery needs to be carefully cleaned.The basic rule of thumb is ‘whatever can go wrong, will go wrong’.
It is not possible to under-estimate the importance of ensuring that data is as accurate as possible before analysis takes place. It is not uncommon for data analysts to have to reject almost all data from assessment when it proves too inconsistent and anomalous to include.Data entry programmes can help reduce the error but ultimately robust processes, checks, monitoring and staff training are required to minimise errors as much as possible. Even with all of these in place, it is likely that some erroneous data will be discarded during dataanalysis.
Once cleaned, it is important for data files to be built around a scaffold. This is called the codebook and should be created in advance of data entry. The codebook contains all the needed information about every piece of data. This includes the name for each variable, variable characteristics such as whether the data is a number or a word, data parameters (for example the maximum and minimum ages of children in a particular grade), what codes should be used for missing data and so on. Without a codebook, data entry will be chaotic and the likelihood of error will increase.
It is important that data entry operators and data analysts are provided with the codebook and training on all of the variables they will be handling.At this stage data is often transferred from a spreadsheet such as Excel into a more sophisticated software such as SPSS orSAS. One of the advantages of doing so is the use of syntax, and the ability to record exactly what syntax was used in each process, can help in the identification of errors at a later date. If syntax is not available, detailed records about how data was altered and what changes this caused need to be kept.
To find out more about data management, move to #Advanced.
 ADVANCED
ADVANCED
“You should look at this section if you have a good understanding of data management and would like to extend your knowledge.”
Data management is often overlooked in the rush to produce results from assessment programmes but in fact it plays a critical role in ensuring that reports are able to provide an accurate picture of student performance. Experienced data analysts often say that ‘everything that can go wrong, will go wrong’ in data management processes. This means predicting problems, setting up clear protocols to avoid them, adequately training staff in their functions, ensuring that every step in the process is recorded in detail and quality assuring everything.
A critical phase in data analysis is theprocess and it is essential that this is not skipped or done superficially. Generally, data cleaning is considered as incorporating a detailed review of accuracy, consistency, completeness, uniformity and validity. It is important to note that data cleaning is not only a technical process. Instead, it also involves value judgement s, for example about when to remove data that cannot be validated and appears to be flawed, often as a result of possible cheating.
Data management can be a highly complex process as the illustration below–which shows the data management model used in PISA–illustrates.
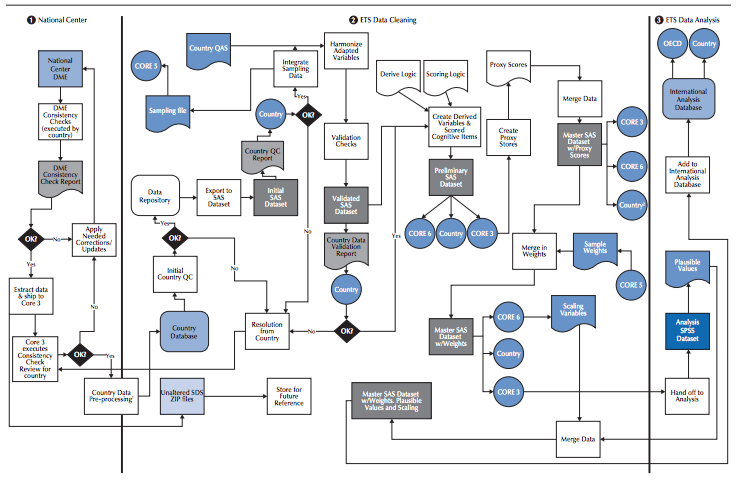
PISA Technical Report, https://www.oecd.org/pisa/sitedocument/PISA-2015-Technical-Report-Chapter-10-Data-Management-Procedures.pdf
Key components include:
- rigorous, robust, multi-stage and consistently followed data cleaning processes;
- the development of a codebook to identify exactly how raw data collected from assessment instruments is structured into a data file;
- data transfer protocols to identify the source, contents, manipulation and access of data;
- data security, in which every step in the data collection, entry and transfer process is documented and monitored;
- the training and actions of all those involved at any step of the data handling process, as well as the quality assurance of their work; and
- the software that is used, for data entry, data management and data cleaning.
It is important to note the phrase ‘rubbish in, rubbish out’. Data analysis can only produce insights based on the data that is fed into software. Unless there has been a robust process for entering, cleaning and managing data that is clearly documented, any results derived from an assessment should be regarded with a high degree of caution. At best, results maybe somewhat misleading, at worst they may paint a completely inaccurate picture of student performance, hence undermining the purpose of doing assessment in the first place.